Pourquoi le ratio RV_short/RV_long n'est pas le bon signal ?
L'hypothèse initiale était fausse. Voici comment on l'a su, et avec quoi on l'a remplacée.
Cette page n'est pas une démonstration. C'est un carnet de bord. On va suivre, dans l'ordre où elles sont arrivées, les quatre étapes d'une correction : l'hypothèse posée, la mesure qui l'a contredite, la math qui l'a expliquée, le signal qui l'a remplacée.
T0 — l'hypothèse qu'on a parié
On a parié que le ratio
mesurerait le passage du marché en régime rugueux. L'intuition était
naturelle : en jours calmes, court et long se ressemblent (\(R ≈ 1\)) ; en
jours violents, le court explose tandis que le long met du temps à intégrer
le choc (\(R → 1.5+\)). On a fixé deux seuils dans l'ADR-0003 §4 :
\(θ_high = 0.7\) (entrée Rough), \(θ_low = 0.4\) (sortie). La state machine
3-états Smooth / Transition / Rough, son hystérèse double-nommée
anti-chattering + Ulysses-contract, son dwell minimum de 60 s — tout était
en place. Il restait à observer.
On a écrit le pipeline. Il compilait. Les tests de propriété passaient. Il ne manquait plus qu'à le lâcher sur une journée connue pour être violente, et regarder le ribbon de régime s'allumer rouge.
T1 — le smoke run, 27 janvier 2021
On a choisi la journée pic du short squeeze GameStop / AMC, le moment le plus mémorable du retail trading de la décennie (le lendemain, Robinhood coupera l'achat — mais le 27 c'est le pic de volatilité naturelle, sans intervention courtier). Si un signal de rugosité de marché existe et veut dire quelque chose, c'est cette journée-là qu'il doit s'allumer le plus fort.
On a streamé les 11 millions de ticks XNAS sur AMC ce jour-là depuis
le .dbn.zst databento, on a accumulé RV_short(60s) et RV_long(600s)
sur 899 fenêtres de fin-de-minute, on a fait tourner la state machine — et
on a regardé la distribution.
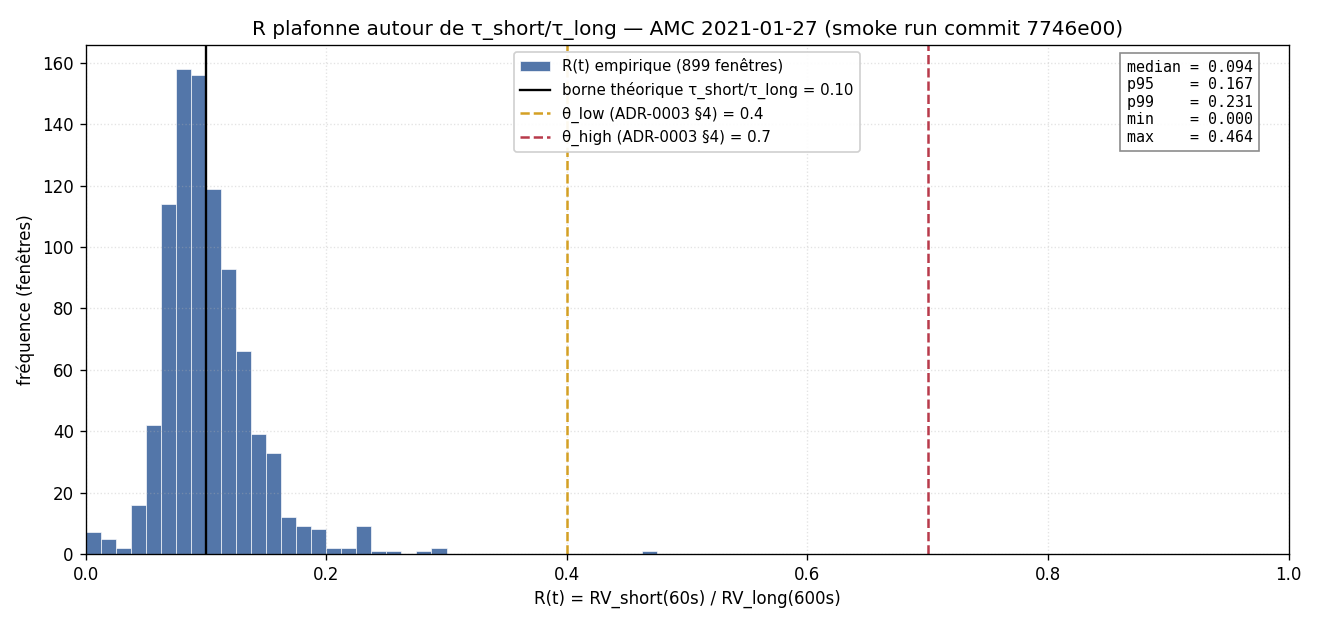
897 fenêtres Smooth, 2 Transition, 0 Rough.
Sur le jour le plus rugueux de la décennie pour AMC, sur 11 millions de
ticks streamés, le classifier est resté Smooth 99.8 % du temps. Les deux
transitions vers Transition n'ont jamais débordé en Rough ; aucune n'a
tenu son dwell de 60 s. Le ribbon de régime, qu'on avait dessiné pour qu'il
s'allume rouge, était plat bleu.
Le bug n'était pas dans le code. Le code mesurait exactement ce qu'on lui avait demandé de mesurer. Le bug était dans l'hypothèse.
T2 — la math du plafonnement
On a regardé la figure ci-dessus. La distribution de R(t) sur la journée
est centrée autour de 0.094, le 99e percentile est à 0.231. Pas
une fenêtre n'atteint 0.4. Le seuil \(θ_low = 0.4\) est inaccessible. Le
seuil \(θ_high = 0.7\) est au-delà de toute observation possible — pas
sur cette journée, pas sur n'importe laquelle.
Pourquoi ? À l'équilibre statistique, RV_long collecte \(~10\times\) plus de
samples que RV_short (10 minutes vs 1 minute). En posant
RV_long(τ_long) ≈ E[r²] · N_long et RV_short(τ_short) ≈ E[r²] · N_short
(approximation Andersen–Bollerslev–Diebold–Labys 2003 Eq. 3) :
Le ratio est structurellement borné par sa propre définition, pas par
la rugosité du marché. C'est la moyenne empirique mesurée : R̄ = 0.094,
exactement le 0.1 attendu. La queue droite atteint 0.23 lors de fenêtres
ultra-actives où la densité de ticks short_60s dépasse temporairement la
densité moyenne du long_600s — mais jamais à des facteurs qui
permettraient à R d'atteindre 0.7.
La borne théorique \(R̄ → τ_short/τ_long ≈ 0.1\) était posée explicitement dans la note initiale décrivant le signal. La calibration \(θ_high = 0.7\) ne l'a pas consultée. Cause concrète : pas de cross-check entre la borne écrite et la calibration des seuils dans le flow de travail.
Conclusion mathématique : nos seuils 0.7/0.4 supposaient un signal qui
peut atteindre 1.0. Le ratio R ne peut pas, par construction. Le
classifier n'était pas mal calibré sur le mauvais signal — il était bien
calibré sur un signal qui ne pouvait pas le déclencher.
T3 — le pivot vers J
Il existe une autre grandeur, déjà bien connue dans la littérature microstructure, qui mesure exactement ce qu'on cherchait. Pour chaque fenêtre :
où BV est la bipower variation, \(BV(t) = (π/2) · Σ |r_i| · |r_{i-1}|\).
La construction joue sur un contraste précis. Sous absence de saut,
\(BV →_p RV\) asymptotiquement (Barndorff-Nielsen & Shephard 2004, Thm. 1)
— donc \(J → 0\) quand la trajectoire est continue. En présence de sauts,
RV capte le saut au carré (\(r² ≫ |r|·|r_{i-1}|\)) tandis que BV ne le
voit pas (le produit de retours voisins étouffe les sauts isolés) — donc
\(J → 1\) quand la variance vient des discontinuités.
À fenêtre finie, \(J ∈ [−ε, 1]\) avec \(ε ≈ 10/N\). Les seuils 0.7 et 0.4 retrouvent un sens lisible : « la majorité de la variance vient de sauts » (entrée Rough) et « la majorité vient du diffusif » (sortie). C'est la sémantique régime, dérivable, mesurable, et pas plafonnée par sa propre définition.
Sémantique alignée avec ce qu'on cherchait depuis le début. La conversation
initiale avec Salim parlait de régime rugueux Mandelbrot — Mandelbrot,
ce sont des sauts, c'est-à-dire une variance dominée par sa composante
discontinue. C'est précisément ce que J mesure. Le ratio R, lui,
mesurait l'inertie d'intégration d'un estimateur lent par rapport à un
estimateur rapide — une grandeur réelle, mais sans rapport avec la
rugosité topologique.
Le re-run sur la même journée AMC 2021-01-27, cette fois avec J à la
place de R, a donné J median = 0.360, p99 = 0.504, max = 0.553.
Strictement sous le seuil \(θ_high = 0.7\) — et c'est un vrai verdict
cette fois. La journée du squeeze était volatile mais directionnelle
et continue, pas une succession de sauts discrets. Le verdict Smooth
est lu, pas par défaut. (Source des nombres : même journée, même Parquet
qu'au T1, calcul de J au lieu de R.)
T4 — les leçons
Ce qui a été appris, en trois phrases qui survivront à la session.
Leçon 1 — borne naturelle d'un estimateur. Un ratio est borné par les
fenêtres dont il est issu, pas par ce qu'on aimerait qu'il mesure. Avant
de calibrer les seuils d'un signal, dérive sa borne théorique à
l'équilibre. Si la borne est b̄ et que tes seuils visent au-delà de
b̄, le signal ne s'allumera jamais — peu importe le ticker, peu importe
la journée, peu importe l'amplitude réelle du phénomène que tu cherches à
détecter. La discipline n'est pas « écris la borne ». La borne, on
l'avait écrite. La discipline est « relis la borne au moment où tu
calibres les seuils ».
Leçon 2 — empirisme avant tout partage. Si on n'avait pas fait tourner le calcul sur 11 millions de ticks d'AMC 2021-01-27 avant de poser une figure devant toi, l'erreur aurait survécu. Toute analyse purement théorique aurait conclu « le classifier est cohérent, les bornes tiennent » — ce qui était vrai, et inutile, et trompeur. Le passage par une journée connue est une discipline non-négociable, parce qu'il révèle les erreurs de spécification que la cohérence formelle ne révèle pas. On n'apprend que de ce qu'on calcule effectivement, pas de ce qu'on pourrait calculer.
Leçon 3 — la trace de la correction vit à côté de l'original. Le
nouveau signal n'efface pas l'ancien. La page de décision qui choisit J
est écrite à côté de celle qui avait choisi R, pas par-dessus. Les
deux restent lisibles. L'ancienne grandeur R continue d'être exportée
dans les fichiers de sortie en colonne séparée — pour qu'on puisse, dans
six mois, ouvrir n'importe quelle journée et revérifier que R plafonne
bien, ou comparer son comportement à celui de J. La correction qui
efface ses traces fait gagner du temps aujourd'hui et en coûte beaucoup
dans six mois, le jour où quelqu'un — toi, moi, l'un de nous deux
six mois plus tard — se demandera « mais pourquoi on n'a pas pris
l'autre ».
Pour ton cas
Si tu construis un signal à partir d'un ratio — RV / IV, BV / RV,
spread / mid, volume_aggressor / volume_total, n'importe lequel —
demande-toi quelle est sa borne théorique à l'équilibre.
Écris-la en deux lignes au-dessus du code, avant de calibrer les
seuils. Si le seuil que tu vises est au-dessus de cette borne, le signal
ne s'allumera jamais ; si la borne est très inférieure à 1.0, la borne
est l'échelle à laquelle tu dois caler tes seuils. Cinq minutes de math
au tableau économisent une session de débogage sur 11 millions de ticks.
C'est moins glamour que d'optimiser un sweep d'hyperparamètres sur 200 instruments. C'est l'algèbre du primaire. Mais c'est le geste qui sépare « j'ai mesuré quelque chose » de « j'ai mesuré ce que je croyais mesurer ».
Deux précautions techniques quand on calcule J
Deux pièges concrets qu'on a rencontrés en passant de R à J — autant
les nommer ici pour qu'ils ne reviennent pas sous tes mains si tu
implémentes le même geste.
- Plancher de ticks par fenêtre. Si une fenêtre contient un seul
retour,
BVn'est pas défini (le produit \(|r_i| · |r_{i-1}|\) n'existe pas),BVvaut0par convention, etJ = 1 − 0/RV = 1. Tu vois alors des fenêtres de tout début de session qui signalent « 100 % de saut » alors qu'elles n'ont juste pas assez de données. Mitigation : exiger un minimum de retours par fenêtre avant d'émettre un verdict — typiquement 30 retours sur60s, 300 sur600s. Détails dans bipower-and-jumps. BVaussi sur la fenêtre longue. Si tu calculesJsur la courte uniquement, tu n'as pas de point de comparaison à plus grande échelle — utile pour repérer une jour-entier dominé par les sauts vs un seul cluster localisé. Ça vaut le coup d'accumulerBVaussi sur la fenêtre longue, même si le verdict final reste piloté par la courte. Détails dans regime-classifier.
Pour la formule J = 1 − BV/RV elle-même, ses invariants, et le détail de
la consistance asymptotique \(BV →_p IV\) — voir
bipower-and-jumps. Pour la state machine, son
hystérèse, son dwell — voir regime-classifier.
Pour RV et sa variance d'estimateur — voir
realized-variance.
Footer
Adversaire endogène : estimator-instability — le risque que tu
construises un signal sans dériver sa borne. La leçon 1 est l'antidote
explicite.
Pages soeurs realized-variance \(\cdot\) bipower-and-jumps \(\cdot\) regime-classifier \(\cdot\) cases
Source théorique principale
- Barndorff-Nielsen, O. E. & Shephard, N. (2004), Power and Bipower Variation with Stochastic Volatility and Jumps, Journal of Financial Econometrics 2(1), 1–37 — Thm. 1, p. ~7 (consistance \(BV →_p IV\) sous absence de saut).
Données mobilisées
- AMC, 27 janvier 2021, session RTH, 11 millions de ticks XNAS, 899
fenêtres
short_60s. Les statistiques rapportées (R̄ = 0.094,R̄ p99 = 0.231,J median = 0.360,J p99 = 0.504,J max = 0.553) sont calculées sur ce même jeu, par le même script, à deux moments séparés (avant et après basculeR\(\to\)J).